提要
在JDK8中,有多种垃圾回收算法,比如Prallel GC,CMS,G1
概述
G1收集器是同时包含了年轻代,和老年代收集的,是ZGC更新前的垃圾回收算法
应用场景
就目前而言、CMS还是默认首选的GC策略、可能在以下场景下G1更适合:
- 服务端多核CPU、JVM内存占用较大的应用(至少大于4G)
- 应用在运行过程中会产生大量内存碎片、需要经常压缩空间
- 想要更可控、可预期的GC停顿周期,防止高并发下应用雪崩现象
内存模型
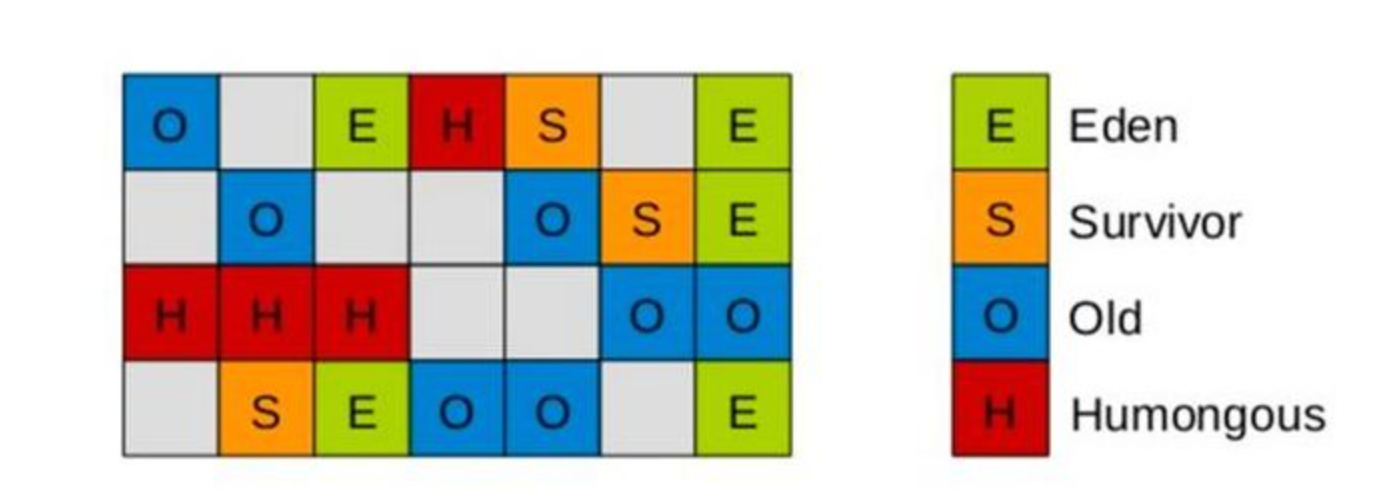
G1将堆内存切分成很多个固定大小的区域,每个是连续范围的虚拟内存。
堆内存中一个区域的大小可以通过 -XX:G1HeapRegionSize参数指定(最小1M,最大32M)
默认情况下堆内存均分成2048份
分代方法
对于每个region,通过不同标记从逻辑上映射成Eden,Survivor和老年代。
除了这几种分代外,还有第四种类型,被称为巨型区域,Humongous Regions,用于存储超过50%标准region大小的喜爱那个设计的。如果一个H区装不下一个巨型对象,那么G1会寻找连续的H分区来存储。为了能找到连续的H区,有时候不得不启动Full GC。
回收阶段(global concurrent marking)
初始标记 inital Marking
这个阶段是STW(Stop the World )的,所有应用线程会被暂停,标记出从GC Root开始直接可达的对象。
tips: 哪些对象是GC Root(static 变量,栈上的变量(类型参数,局部变量,临时值),JNI),GC的过程是找出活的对象,并把其余空间认定为“无用”,而不是找出所有死掉的对象
G1执行的第二阶段:并发标记
从1阶段搜索出来的GC ROOTS开始对对象进行可达性分分析,找出存活对象
最终标记(标记那些在并发标记阶段发生变化的对象,将被回收)
筛选回收(首先对各个Regin的回收价值和成本进行排序,根据用户所期待的GC停顿时间指定回收计划,回收一部分Region)
最后,G1中提供了两种模式垃圾回收模式,Young GC和Mixed GC,两种存在Stop The World(STW)的阶段。
GC模式
Young GC
当Eden region使用达到最大阈值并且无法申请最够内存时,会触发young GC,每次younggc会回收所有Eden以及Survivor区,并且将存活对象复制到Old区以及另一部分的Survivor区。
YoungGC的回收过程如下:
- 根扫描,跟CMS类似,Stop the world,扫描GC Roots对象。
- 处理Dirty card,更新RSet.
- 扫描RSet,扫描RSet中所有old区对扫描到的young区或者survivor去的引用。
- 拷贝扫描出的存活的对象到survivor2/old区
- 处理引用队列,软引用,弱引用,虚引用
mixed gc
当越来越多的对象晋升到olg region后,虚拟机会触发mixed gc,回收整个young region和一部分old region。这里需要注意,是一部分老年,也不是全部老年代,从而可以对垃圾回收的耗时进行控制
G1没有full GC的概念,需要full GC时,调用 serial Old gc 进行全堆扫描。所以Mixed GC不是Full GC,它只能回收部分老年代的Region,如果Mixed GC实在无法跟上程序分配内存的速度,导致老年代填满无法继续进行Mixed GC,就会使用serial old GC(Full GC)来收集整个GC heap。 所以本质上,G1是不提供Full GC的。
应用场景
如果应用程序使用CMS或ParallelOld垃圾回收器具有一个或多个以下特征,将有利于切换到G1:
- Full GC持续时间太长或太频繁
- 对象分配率或年轻代升级老年代很频繁
- 不期望的很长的垃圾收集时间或压缩暂停(超过0.5至1秒)
最佳实践
停顿(STW)预测模型
G1收集器突出表现出来的一点是通过一个停顿预测模型根据用户配置的停顿时间来选择CSet的大小,从而达到用户期待的应用程序暂停时间。通过 -XX:MaxGCPauseMillis 参数来设置。这一点有点类似于ParallelScavenge收集器。关于停顿时间的设置并不是越短越好。
设置的时间越短意味着每次收集的CSet越小,导致垃圾逐步积累变多,最终不得不退化成Serial GC。
停顿时间设置的过长,那么会导致每次都会产生长时间的停顿,影响了程序对外的响应时间
当Mixed GC赶不上对象产生的速度的时候就退化成Full GC,这一点是需要重点调优的地。
不需要手工设置新生代和老年代的大小
G1收集器在运行的时候会调整新生代和老年代的大小。通过改变代的大小来调整对象晋升的速度以及晋升年龄,从而达到我们为收集器设置的暂停时间目标。
设置了新生代大小相当于放弃了G1为我们做的自动调优。我们需要做的只是设置整个堆内存的大小,剩下的交给G1自己去分配各个代的小即可。
原理 – todo
Rset和卡表
三色标记算法和SATB